
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- jupyter 명령어 모드 단축키
- object detection
- vscode sftp
- Kullback-Leibler Divergence
- 백준 1325번
- YOLO detection
- 프로그래머스 67256번
- 원격서버 로컬 동기화
- 프로그래머스 72410번
- 프로그래머스 67257번
- jupyter 셀 추가 단축키
- 프로그래머스 42885번
- gradient descent optimization
- DeepLabv3+
- 프로그래머스 67258번
- 백준 3190번
- 백준 효율적인 해킹
- augmentation 이후 이미지 확인
- Optimization algorithms
- 프로그래머스 43164번
- 가상환경 제거
- zip 압축해제 명령어
- 카카오 보석 쇼핑
- 프로그래머스 42839번
- 프로그래머스 보석 쇼핑
- 가상환경 확인
- 프로그래머스 42883번
- MMdetection
- os 확인 명령어
- pytorch 이미지 확인
- Today
- Total
소소한 블로그
[논문리뷰] FaceNet에 대한 이해 본문
이번에는 FaceNet 논문에 대해서 정리해보고자 합니다.
(논문링크 - FaceNet: A Unified Embedding for Face Recognition and Clustering)
FaceNet은 2015년에 발표된
Face verification, recognition, clustering에 쓰이는 embedding 생성 모델입니다.
이 논문을 읽은지는 꽤 되었지만 따로 기록으로 남기진 않았는데,
오늘 정리해보고자 합니다.
그러면 바로 본론으로 들어가겠습니다.
[FaceNet의 주요 특징과 장점]
제가 생각하기에 FaceNet의 주요 특징은
아래와 같이 2가지로 정리할 수 있을 것 같아요.
- 얼굴 사진이 주어지면,
이것을 직접적으로 n차원의 Euclidean space상의 벡터로 mapping 시킬 수 있다는 점 - 훈련을 시킬 때에 'triplet loss'를 사용한다는 점
이로부터 오는 장점은 아래와 같습니다.
- output 형태가 embedding vector이기 때문에,
이전 모델들과는 달리 embedding vector을 직접적으로 optimize 한다는 점 - 적은 차원의 embedding vector를 가지고도 효과적으로 이미지를 표현해낼 수 있다는 점
본격적인 내용에 앞서서
간단하게 FaceNet의 주요 특징과 장점에 대해 정리해봤어요.
이제 조금 더 자세하게 들어가볼게요.
[기존 모델의 한계점]
설명에 앞서,
여기서 언급하는 기존 모델이란 FaceNet이 나오기 전의 모델을 의미합니다.
기존의 face recognition 모델들은
classification layer을 가지는 deep networks을
여러 인물에 대해 학습을 시킵니다.
쉽게 생각하면 하나의 인물을 하나의 카테고리로 삼아,
이미지 분류 모델을 학습시키는 것이죠.
학습이 완료된 후, 중간 layer의 output을 이미지의 representation vector로 삼았습니다.
(참고로 face recognition이란 해당 사진이 어떤 인물인지 판단하는 태스크입니다.)
이 접근법의 단점은 아래와 같습니다.
- 직접적으로 embedding vector를 학습시키지 않는다.
- representation vector의 차원이 크다.
만약 train dataset에는 없는 새로운 인물이 주어진다면,
과연 이미지 분류 모델의 중간 layer의 output이
해당 인물을 잘 표현해내는 representation vector가 될 수 있는가에
대한 의심을 품을 수 있습니다.
또한 representation vector의 차원이 1000단위였는데,
이는 FaceNet에 비하면 매우 큰 차원입니다.
(참고로 FaceNet은 128차원입니다.)
[기존 모델의 한계점 보완]
기존 모델의 한계점을 설명했다는 것은
FaceNet은 위의 한계점을 보완했다는 의미겠죠?
FaceNet은 classifier을 학습시키는 것이 아니라,
128차원의 임베딩 벡터를 직접적으로 학습시킵니다.
'triplet loss'라는 것을 사용하여 deep convolution network를 학습시킴으로써,
이를 가능하게 만들었습니다.
triplet loss를 계산하기 위해서는
아래와 같이 기본적으로 3가지 사진이 한 쌍이 되어야 합니다.
(기준이 되는 사진 - anchor, 기준과 동일한 인물 사진 - positive, 기준과 다른 인물 사진 - negative)
여기서 첫번째와 두번째 임베딩 벡터사이의 거리는 가깝게,
첫번째와 세번째 임베딩 벡터사이의 거리는 멀게끔
학습을 시키는 것이 triplet loss의 개념입니다.
여기에서 대략적으로 FaceNet의 학습방법을 언급했다면,
뒤에 이어서 더 구체적인 학습방법과 여러 실험결과에 대해
정리해보겠습니다.
[Triplet Loss]
triplet loss를 설명하기에 앞서
아래의 figure통해
FaceNet의 모델 구조와 triplet loss에 대한 개념을
다시 한번 간략히 상기시켜보겠습니다.

위의 figure로부터
FaceNet는 deep convolution network의 구조를 가지며,
최종 output은 embedding vector임을 알 수 있습니다.
그리고 모델은 triplet loss를 통해 학습을 진행함을 알 수 있습니다.
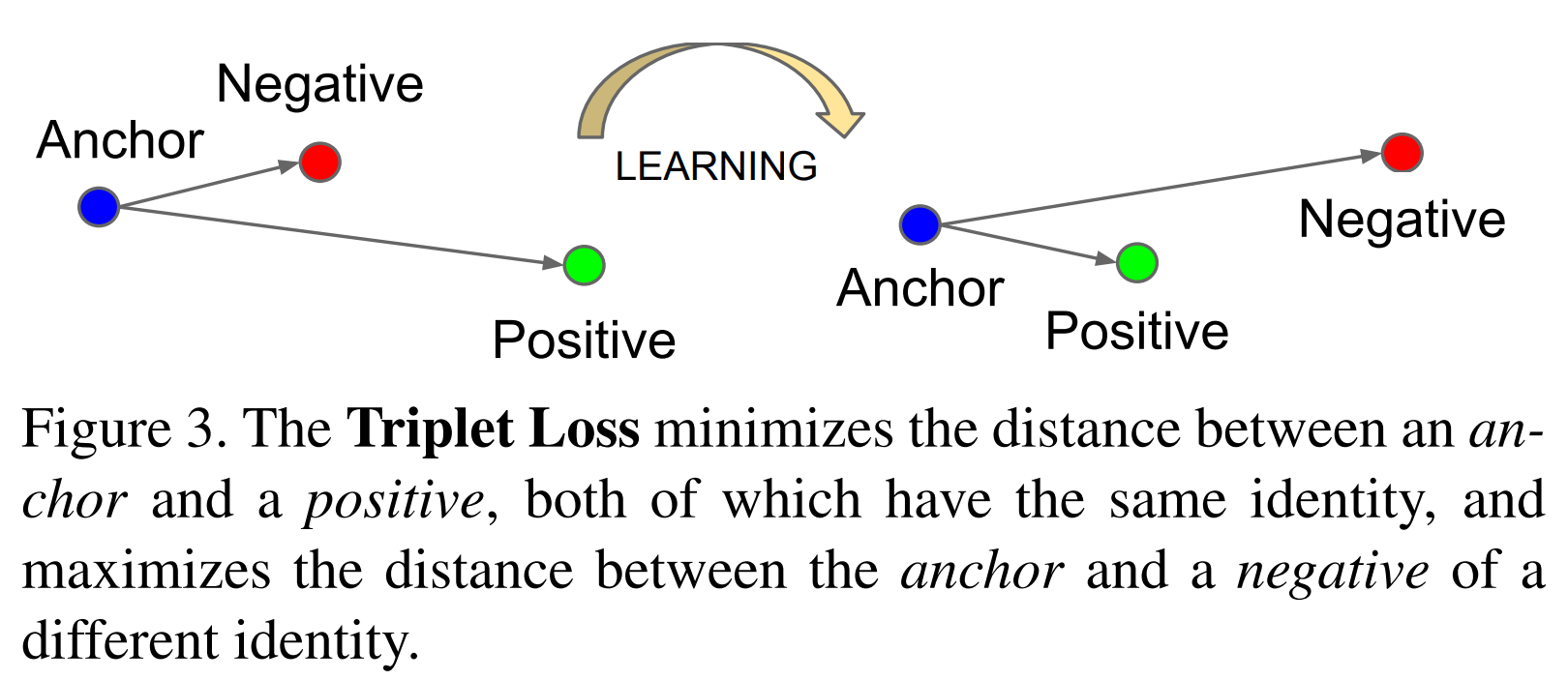
위의 figure는 triplet loss가
anchor와 positive의 embedding vector 사이의 거리는 가깝게
anchor와 negative의 embedding vector 사이의 거리는 멀게
학습시킨다는 것을 표현하고 있습니다.
이제 본격적으로
triplet loss에 대해 알아보겠습니다.
1) Triplet Loss 수식
FaceNet의 embedding vector은 하나의 제약이 있습니다.
embedding vector의 정의를 \(f(x) \in \mathbb{R}^{d}\)로 한다면,
\(\left\|f(x) \right\|_{2} = 1\)라는 제약이 붙습니다.
사실 이 제약은 위의 모델 구조 figure에서 볼 수 있었습니다.
(빨간색으로 표시함)

triplet loss를 수식으로 나타내면 아래와 같습니다.
\[L=\sum_{i}^{N}\left [ \left\|f(x_{i}^{a}) -f(x_{i}^{p})\right\|_{2}^{2}-\left\|f(x_{i}^{a}) -f(x_{i}^{n})\right\|_{2}^{2}+\alpha \right ]_{+},\]
\[\forall(f(x_{i}^{a}),f(x_{i}^{p}),f(x_{i}^{n})) \in \tau \]
여기서 \(\tau\)는 학습데이터에서 만들어질 수 있는
모든 triplet쌍의 집합을 뜻합니다.
\(\alpha\)는 positive와 negative간의 margin을 뜻합니다.
2) Triplet Selection
만약 만들어질 수 있는 모든 triplet쌍을 학습데이터로 활용한다면
생기는 문제점에 대해 생각해보겠습니다.
위와 같은 상황에서
육안으로 봤을 때 다른 사람임을 쉽게 구분할 수 있는 데이터 또한
학습데이터로 많이 활용되게 됩니다.
이 경우 \(\left\|f(x_{i}^{a}) -f(x_{i}^{p}) \right\|_{2}^{2} + \alpha < \left\|f(x_{i}^{a}) -f(x_{i}^{n}) \right\|_{2}^{2}\)의 문제는
해결하기 쉬운 문제가 됩니다.
쉬운 문제들로 인해 정작 중요하게 풀어야 하는 어려운 문제들에 대해서는
잘 학습하지 못하게 됩니다.
이 경우에 모델의 수렴 속도가 느려진다는 문제점이 생깁니다.
그렇다면 어떻게 triplet을 구성해야 할까요.
맞추기 어려운 \(x_{i}^{p}\) (hard positive)와 \(x_{i}^{n}\) (hard negative)를 골라야 합니다.
이를 수식으로 더 풀어서 쓴다면
\(argmax_{x_{i}^{p}}\left\|f(x_{i}^{a}) -f(x_{i}^{p}) \right\|_{2}^{2}\)을 만족시키는 \(x_{i}^{p}\)를 고르고
\(argmin_{x_{i}^{n}}\left\|f(x_{i}^{a}) -f(x_{i}^{n}) \right\|_{2}^{2}\)을 만족시키는 \(x_{i}^{n}\)을 고르는 것이 이상적입니다.
하지만 전체 데이터셋에 대해 위를 만족하는
\(x_{i}^{p}\), \(x_{i}^{n}\)를 찾기는 어려운 일이므로
(모든 pair에 대해 거리 계산이 필요하고,
학습데이터에는 잘못 라벨링된 데이터도 존재하기 때문입니다.)
FaceNet에서는 mini-batch마다 triplet을 구성하였습니다.
mini-batch 마다 anchor와 positive sample의 거리가 의미 있으려면,
하나의 배치마다 최소한의 positive sample이 존재해야 합니다.
따라서 배치마다 한 인물당 40개의 이미지를 포함하도록 했습니다.
그런데 FaceNet에서는 mini-batch마다 hard positive와 hard negative를 구성한 것은 아닙니다.
positive에 대해서는 hard positive를 선택하지 않고,
모든 anchor-positive pairs의 조합을 사용하였습니다.
논문에서는 이렇게 했을 때 train이 더 안정적이고 더 빠르게 수렴했다고 합니다.
다만 negative sample에 대해서는 hard negative를 이용하였습니다.
아래를 만족시키는 \(x_{i}^{n}\)를 만족시키는 negative sample을 고릅니다.
\(\left\|f(x_{i}^{a}) -f(x_{i}^{p}) \right\|_{2}^{2} < \left\|f(x_{i}^{a}) -f(x_{i}^{n}) \right\|_{2}^{2}\)
위를 만족시키는 negative sample은 margin \(\alpha\)경계 안에 들어있는 sample일 수 있습니다.
[Deep Convolutional Networks]
위에서 FaceNet은 Deep Convolutional Networks를 활용한다고 하였습니다.
여기에서는 어떤 Deep Convolutional Networks를 가지는지
간략히 짚고 넘어가겠습니다.
크게 2가지 타입으로 나눠 FaceNet을 실험했다고 합니다.
parameter의 개수와 FLOPS의 값과, 성능 간의 trade-off로 인해
2가지 유형으로 나눠 FaceNet을 실험해봤다고 합니다.
첫번째 유형은 Zeiler&Fergus architecture 기반으로 한 구조입니다.
아래와 같은 layer를 가집니다.
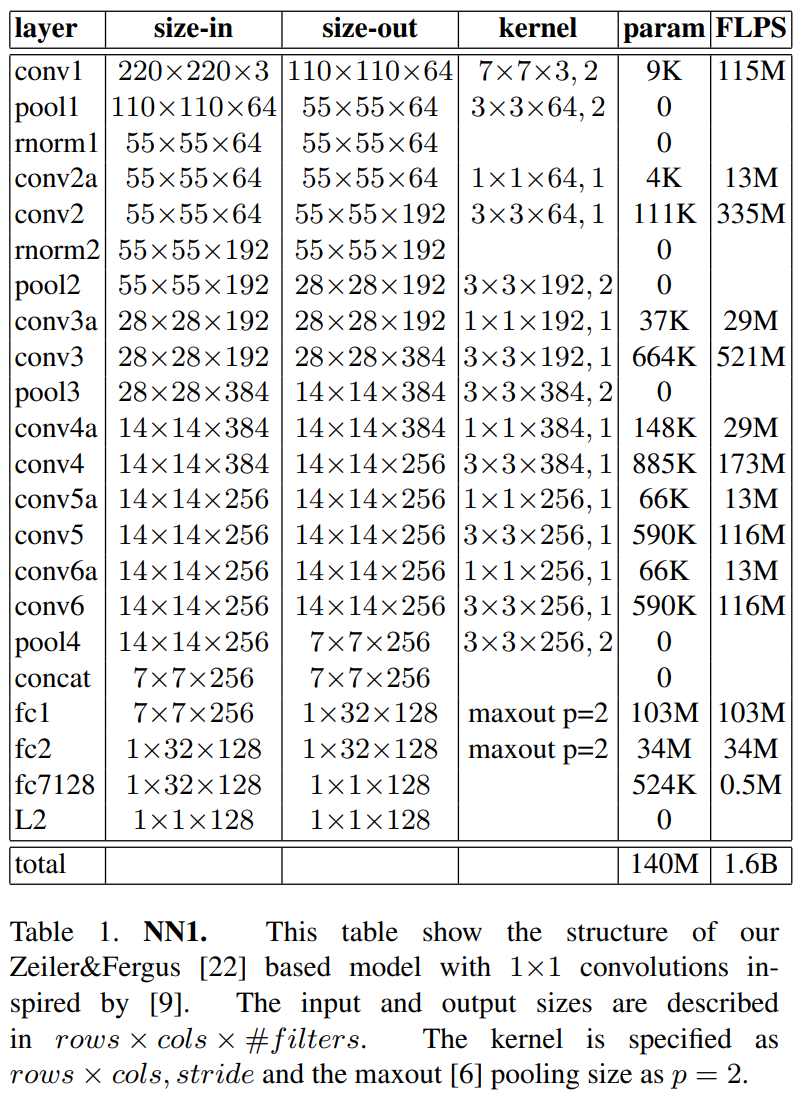
두번째 유형은 GoogLeNet 구조를 활용한 네트워크입니다.
이는 첫번째 유형에 비해 파라미터 개수가 약 20배 작고,
FLOPS는 약 5배 적다고 합니다.
모델 크기가 작아 핸드폰과 같은 기기에서 잘 작동할 수 있다고 합니다.
이 유형에서는 파라미터 개수와 FLOPS에 따라 4가지(NNS1, NNS2, NN3, NN4)로 나뉩니다.
[Evaluation]
모델의 평가는 face verification task에 대해
자체 평가지표를 정의하여 수행했습니다.
참고로
face verification이란 두 사진이 주어졌을 때,
두 인물이 같은 인물인지 판단하는 태스크입니다.
FaceNet에서는 두 사진이 주어졌을 때
두 임베딩 벡터 사이의 거리가 특정 threshold를 넘는지를 이용하여
같은 인물인지 다른 인물인지 판단하게 됩니다.
\(P_{same}\)을 같은 인물인 두개의 사진쌍의 집합이라고 하고,
\(P_{diff}\)를 다른 인물인 두개의 사진쌍의 집합이라고 정의합니다.
그 후, 아래와 같이 TA(d), FA(d)를 정의합니다.
\[TA(d) = \left\{(i,j) \in P_{same},\textrm{ with }D(x_{i},x_{j})\leq d \right\}\]
\[FA(d) = \left\{(i,j) \in P_{diff},\textrm{ with }D(x_{i},x_{j})\leq d \right\}\]
이는 각각
같은 것을 같다고 판단한 개수,
다른 것을 같다고 판단한 개수를 뜻합니다.
그 후, VAL(d)와 FAR(d)를 아래와 같이 정의하여 모델의 평가지표로 활용합니다.
\(VAL(d) = \frac{TA(d)}{P_{same}}\), \(FAR(d) = \frac{FA(d)}{P_{diff}}\)
평가 데이터셋은 LFW, YouTube Faces, Personal Photos를 활용하였고,
자체 평가지표는 Personal Photos에 대해 적용했다고 합니다.
(나머지는 Face recognition 성능으로 측정)
[Experiments]
논문에서는 아래 실험에 대한 결과물을 소개하고 있습니다.
- 연산과 accuracy간의 trade-off
- CNN 모델 유형마다의 VAL값
- 이미지 퀄리티에 따른 VAL값
- 임베딩 벡터 차원에 따른 VAL값
- 학습데이터 개수에 따른 accuracy값
- LFW 데이터셋과 Youtube Faces DB에 대한 accuracy값
- 자체 데이터인 Personal Photos에 대한 face clustering 성능
이것들을 모두 설명한다면,
글 내용이 너무 길어질 것 같아 생략하도록 하겠습니다.
[Summary]
지금까지 기존 모델의 한계점을 해결한
FaceNet만의 특징과 장점에 대해 알아보았습니다.
한 문장으로 FaceNet을 요약한다면,
triplet loss 학습 방법을 사용하여
이미지로부터 임베딩 벡터를 직접적으로 생성해내는 모델
이라고 요약 가능할 것 같습니다.
논문에서 future work로
에러 케이스를 분석하여 모델을 개선시키고
모델 사이즈와 요구되는 CPU 스펙을 더 낮추는 것을 제시했습니다.
또한 학습속도를 더 짧게 개선시키는 것을 제시했네요.
드디어 끝났습니다!
개인적으로
Face verification model은 한 번도 공부해본 적은 없어서 그런지
FaceNet의 학습 방식이 흥미로웠습니다.
다음에는 또 무엇을 공부해볼지 생각해야겠습니다.
'이론 > 이미지인식' 카테고리의 다른 글
| [논문리뷰] DeepLabv3+의 이해 (0) | 2021.11.27 |
|---|---|
| [논문리뷰] YOLO Object Detection의 이해 (0) | 2021.09.27 |
| [논문리뷰] Faster R-CNN 이해 (2) | 2021.04.12 |
| [논문리뷰] Fast R-CNN 이해 (0) | 2021.03.31 |
| [논문리뷰] R-CNN 이해 (0) | 2021.03.23 |



