
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- object detection
- 프로그래머스 42883번
- 원격서버 로컬 동기화
- 프로그래머스 67257번
- Optimization algorithms
- jupyter 명령어 모드 단축키
- 가상환경 제거
- MMdetection
- Kullback-Leibler Divergence
- 프로그래머스 72410번
- zip 압축해제 명령어
- vscode sftp
- gradient descent optimization
- augmentation 이후 이미지 확인
- 프로그래머스 42885번
- 프로그래머스 67256번
- 가상환경 확인
- 프로그래머스 43164번
- 프로그래머스 보석 쇼핑
- os 확인 명령어
- jupyter 셀 추가 단축키
- 프로그래머스 42839번
- DeepLabv3+
- pytorch 이미지 확인
- 백준 효율적인 해킹
- 백준 3190번
- 카카오 보석 쇼핑
- YOLO detection
- 프로그래머스 67258번
- 백준 1325번
- Today
- Total
소소한 블로그
[논문리뷰] YOLO Object Detection의 이해 본문
9주차에 진행되는 부스트캠프 경연은
Object Detection에 관해 다룹니다.
따라서 팀원들과 이와 관련한 논문을 읽어보기로 했고,
처음 다룰 논문은 YOLO로 정했습니다.
아래는 제가 논문을 읽고 이해한 바를 정리한 글입니다.
YOLO와 기존 다른 모델과의 차이점,
YOLO의 architecture,
training 과정,
장단점,
등에 관해 소개하겠습니다.
[기존 2 stage Object detection과 YOLO의 차이점]
R-CNN과 같은 (논문이 나온 시점 기준으로) 최신 Object dectection 방법은
이미지 안에서 obejct가 존재할만한 region을 추출해내는 과정(region proposal)을 수행한 후에,
추출된 region proposal에서 classification을 수행합니다.
region proposal 과정을 수행한 뒤,
classification을 수행하기 때문에
이런 방법들을 흔히 2 stage라고 부릅니다.
이런 2 stage방법은 구조가 복잡하여 느리고,
각 단계가 각각 학습되기 때문에
최적화가 어렵다는 단점이 있습니다.
YOLO는 2단계를 순차적으로 진행하던 2 stage방법을 1 stage로 바꿉니다.
다시 말하면
YOLO는 region proposal을 수행한 뒤 classification을 진행하는 기존 2 stage 방법과는 달리,
bounding box 좌표 추출과 classification 수행을 동시에 진행하게 됩니다.
아래 사진은 YOLO의 inference 과정을 아주 간략히 보여주는 그림입니다.
convolution 과정을 몇번 거친 후
(여기서는 convolution이 3번으로 표현되었는데 실제로는 더 많습니다.)
결과물로 바로 bounding box와 class 확률이 동시에 구해지게 됩니다.
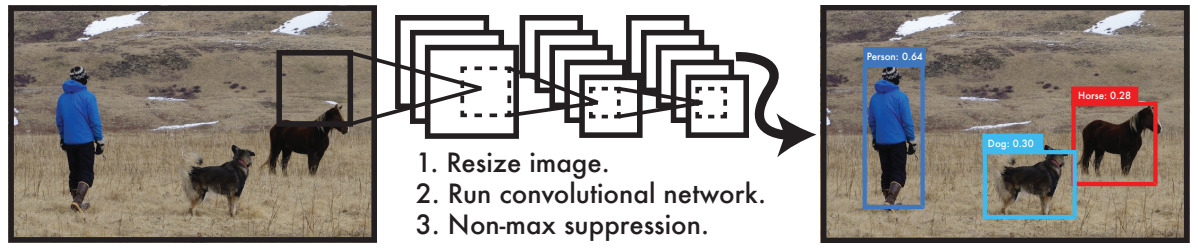
[YOLO의 전체적인 과정]
input 이미지는 S * S grid로 구분됩니다.
각 grid cell에서는 B개의 bounding box를 추측하게 되고,
각 bounding box 마다 실제로 물체가 있는지에 관한
confidence score을 연산하게 됩니다.
bounding box 위치 정보는 4가지 변수(x, y, w, h)로 표현됩니다.
x := bounding box의 중심 좌표(가로축)
y := bounding box의 중심 좌표(세로축)
w := bounding box의 width
h := bounding box의 height
bounding box의 confidence score은 아래와 같이 정의됩니다.
$$Pr(Object) * IOU_{pred}^{truth}$$
따라서 각 bounding box는
x, y, w, h, confidence score 총 다섯가지 정보를
가지게 됩니다.
그리고 이와 동시에
각 grid cell (bounding box와 grid cell은 다른 개념입니다.
하나의 grid cell마다 B개의 bounding box를 추측합니다.)은
object에 대한 class 조건부 확률을 추측합니다.
$$Pr(Class_{i}|Object)$$
inference 과정에서는 각 박스에 대한 class-specific confidence를
아래와 같은 식으로 구합니다.
$$Pr(Class_{i}|Object) * Pr(Object) * IOU_{pred}^{truth} = Pr(Class_{i}) * IOU_{pred}^{truth}$$
위의 전체적인 과정을 그림으로 표현하면 아래와 같습니다.
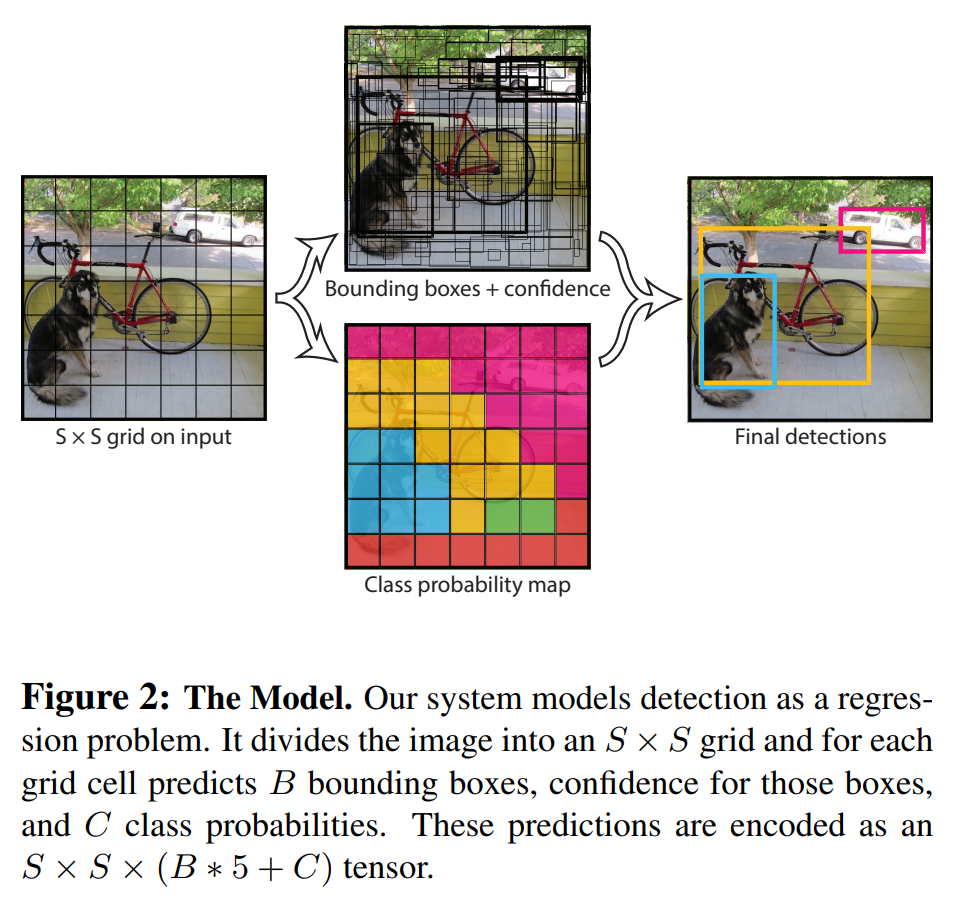
[YOLO의 Network Design]
YOLO의 Network는 아래와 같이 구성되어 있습니다.
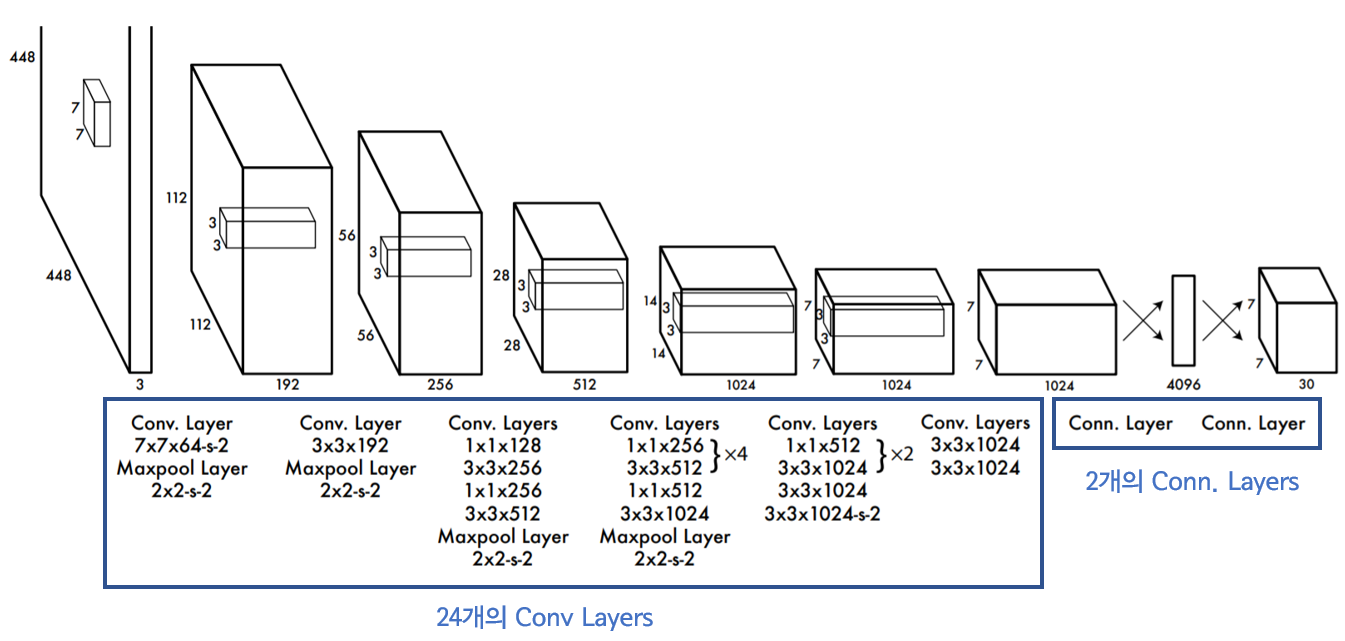
YOLO의 architecture는 주로 convolution layer로 구성되어 있습니다.
24개의 convolution layer를 통해 이미지의 feature를 추출해내는 작업을 거친 뒤,
2개의 fully connected layer를 통해 bounding box 좌표와 class 확률을 추측합니다.
[YOLO의 training 과정]
1. 처음 20개의 convolution layers 사전학습
YOLO는 처음부터 모든 layer를 학습시키지 않습니다.
처음 20개의 convolution layer만 따로 떼어
뒷단에 2개의 layer만 붙인 뒤
ImageNet 2012 데이터셋에 대한 classification 문제를 학습시킵니다.
이 과정을 통해 이미지에 대한 general한 특징들을
학습할 수 있게 될 것이라 추측됩니다.
그 후 앞서 학습시킨 20개의 convolution layer에다가
4개의 convolution layer와 2개의 fully connected layer를 붙여
object detection에 관한 task를 학습시킵니다.
object detection은 정교한 추측을 해내야 하기 때문에
YOLO를 학습시킬때는 input image에 대한 크기를
224 * 224를 448 * 448로 크기를 키워 학습을 진행켰다고 합니다.
최종 layer의 output의 결과물은 bounding box 좌표와 각 class별 확률입니다.
2. activation function, loss
activation function으로는 leaky relu를 사용했으며
loss는 sum-squared error을 사용했습니다.
(sum-squared error을 사용한 이유는
optimize를 하는 과정이 비교적 단순하기 때문이라고 소개하고 있습니다.)
하지만 YOLO에서 단순히 sum-squared error을 사용했을 때에는 문제점이 생기게 되는데요,
어떤 문제점이 있는지
그리고 YOLO에서는 이를 해결하기 위해 어떤 방법을 채택했는지 소개하겠습니다.
문제점
- localization error(bounding box의 위치 정보에 대한 loss)와
classification error에 대한 weight를 동일하게 주는 것은 이상적이지 않다. - 모든 grid cell에 물체가 포함된 것은 아니다.
이것은 종종 confidence score 계산에 부정적인 영향을 끼친다.
(저의 언어로 설명하자면,
먼저 grid cell이 49개라고 하고 B의 값이 2개라고 가정하겠습니다.
그렇다면 총 98개의 bounding box가 생길 것 입니다.
또한 실제로 물체가 있는 bounding box는 2개이고
물체가 없는 bounding box는 96개라고 가정하겠습니다.
물체가 존재하지 않은 grid cell에 대한
bounding box의 confidence error의 제곱이 0.1이라고 가정한다면
물체가 없는 bounding box의 총 confidence error의 제곱합은 0.1 * 96 가 됩니다.
하나씩 보면 조그만 값일지 모르겠지만,
여러개가 모이면 loss의 대부분을 차지할 수 있습니다.) - 큰 박스의 오차와 작은 박스의 오차의 weight를 동일하게 주는 것은 이상적이지 않다.
(저의 언어로 설명하자면,
실제 bounding box의 크기를 100 * 100이라고 했을 때
95 * 95로 예측한 것과
실제 bounding box의 크기를 6 * 6이라고 했을 때
1 * 1로 예측한 것이 있을 때
둘의 height와 width에 대한 error 값을 동일하게 주는 것은 이상적이지 않습니다.)
해결책
- bounding box 위치 정보에 대한 loss에 대해 weight를 크게 준다.
- 물체가 포함되어 있지 않은 부분에 대한 confidence prediction에 대한
weight는 작게 준다. - bounding box의 width와 height는
값을 그대로 쓰는 것이 아닌
square root(제곱근) 적용한 값으로 error을 처리한다.
아래는 완성된 loss 식입니다.
각 부분이 무엇을 뜻하는지 정리해봤습니다.
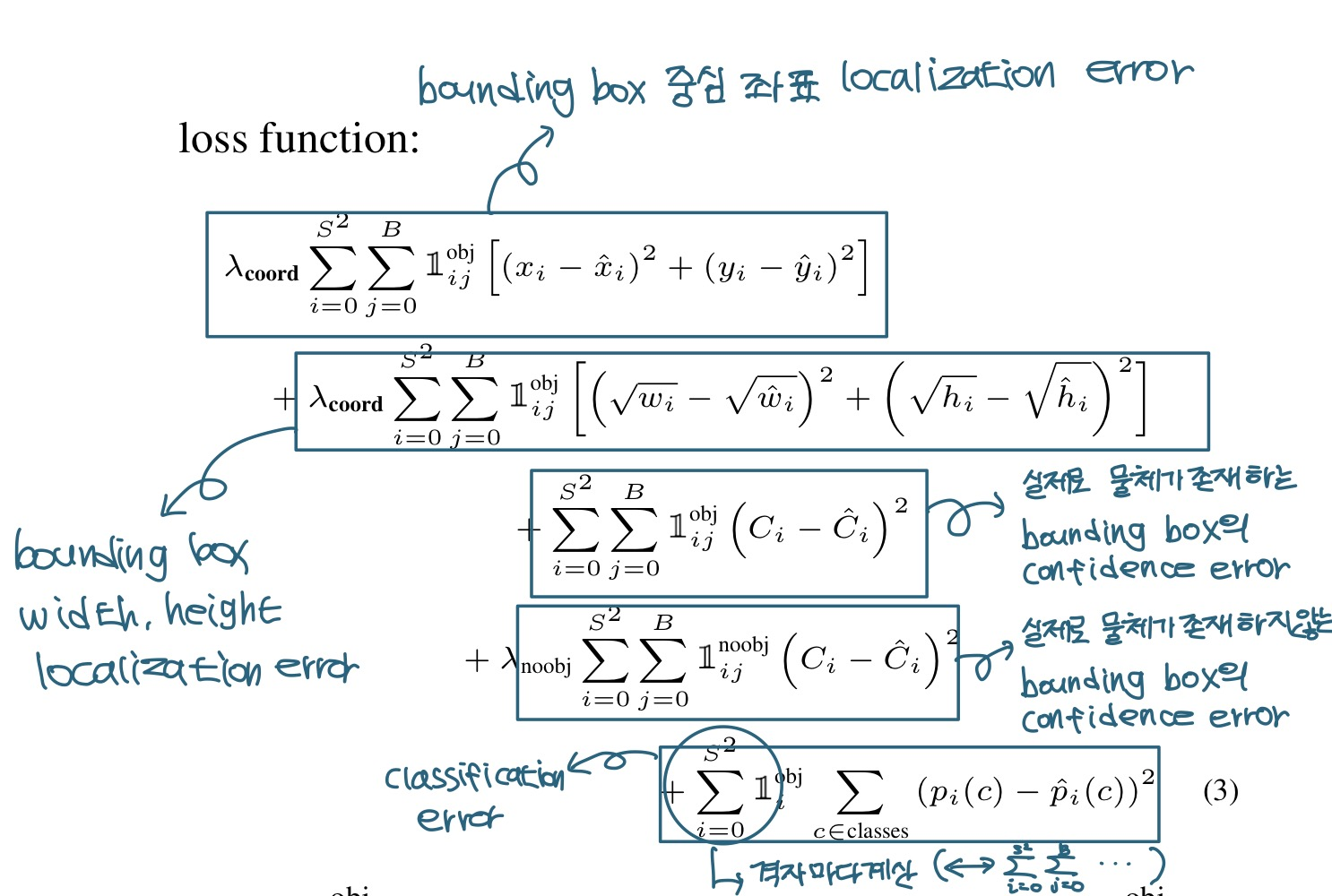
참고로 training시에는 여러 bounding box를 구하게 되는데,
하나의 cell당 IOU를 기준으로 제일 높은 값을 가지는 bounding box를 선별해내는 과정을
거친다고 합니다.
[중복된 bounding box 제거]
하나의 object당 하나의 bounding box가 나와야 하므로
만약 하나의 object에 여러개의 bounding box의 결과물이 나왔다면,
(예를 들면 object가 아주 큰 크기를 가질때 이런 결과물이 나올 수 있습니다.)
Non-maximal suppression을 통해 중복된 bounding box를 하나로 통합시킵니다.
[YOLO의 한계]
논문에서는 YOLO의 4가지의 한계점에 대해 소개하고 있습니다.
- 각 grid cell 마다 B개의 bounding box만 추측해내야 한다는 공간적 제약성은
가까이 붙어있는 물체를 판별해내는데에 부정적 영향을 끼친다.
(예를들면 꽃을 object dectection을 한다고 가정하면,
작은 꽃들이 밀집해있는 경우를 상상하면 될 것 같습니다.) - data로 부터 bounding box를 훈련시키기 때문에,
학습데이터에는 없는 특이한 ratio의 bounding box가
test data로 주어진다면 이를 잘 검출해내지 못한다. - 여러개의 down sampling을 사용하기 때문에
상대적으로 디테일하지 못한 feature를 구해낸다. - YOLO의 주요한 error는 부정확한 localization에서 일어나는데
그 이유는 작은 bounding box에서의 localization 에러와
큰 boudning box에서의 localization 에러에 대한 가중치가 동일하기 때문이다.
(제 추측으로는 width와 height는 어느정도 이를 해결했지만,
중심점에 관해서는 이를 반영하지 못했기 때문에
이런 한계점을 소개한 듯 합니다.)
[YOLO의 장점]
YOLO는 기존과 비교하여 아래와 같은 장점을 가지게 됩니다.
- 매우 빠르다.
기존의 복잡한 구조를 아주 간단하게 변경했기 때문에 연산 속도가 빠릅니다.
Titan X GPU를 기준으로 batch 처리를 하지 않고 1초당 45개의 사진을 처리할 수 있습니다.
빠른 버전의 YOLO(convolution 연산 횟수를 기존보다 줄임)는 150개의 사진을 처리할 수 있습니다. - prediction을 할 때, 이미지의 전체적인 부분을 고려한다.
YOLO는 traing, test과정에서 이미지의 전체적인 영역을 고려하기 때문에
class에 관한 contextual information(문맥적인 정보)을 잘 고려하게 됩니다.
또한 Fast R-CNN과 비교하여
back ground를 물체라고 잘못판단하는 경우가 적습니다.
(추측:
YOLO는 전체적인 영역을 모두 고려하기 때문에
전체적인 이미지의 문맥 정보를 잘 읽게 되고
그렇기 때문에 물체와 배경을 더 잘 구분할 수 있다는 의미인듯 합니다.) - object에 관한 일반적인 representation을 잘 학습한다.
자연에서 찍힌 이미지로 학습한 YOLO를 가지고
미술 작품 안에서의 object detection을 테스트할 때,
기존의 다른 방법들 보다 더 성능이 좋았다고 합니다.
이로써 YOLO에 대한 리뷰를 마쳤습니다.
YOLO가 기존 2 stage detection과 비교하여
어떤 architecture을 가지는지,
또한 이러한 차이점으로 인해
어떠한 장단점을 가지게 되는지 리뷰해봤습니다.
제가 논문을 읽으면서 들었던 생각은 아래와 같았습니다.
접은글로 작성했습니다.
'사실상 YOLO의 architecture 자체는
2 stage object detection에 비하면
오히려 매우 간단하게 보인다.
또한 이미지에 관련된 연구는
classification이 먼저 진행되고 object detection이 활발히 진행되었을 것 같은데,
classification에 쓰이는 방법을 활용해
obect detection을 풀어내고자 한다면
처음 떠올릴 수 있는 network는
2 stage detector보다는 YOLO가 더 친숙한 방법이었을 것 같다.
그럼에도 불구하고
왜 연구자들은 2 stage detector와 같은 복잡한 구조를
먼저 생각하고 연구를 진행했을까?'
였습니다ㅎㅎ
저의 의견은(정말 추측에 불과합니다ㅎㅎ)
연구자들이 생각하기에
사람이 특정 클래스의 물체위치를 판별해낼 때는
1. 먼저 물체가 어디있는지 인식한 뒤
2. 해당 물체가 어떤 클래스인지 인식하는 과정
을 거치는 것이 합리적일 것이라고 추측했던 것 같습니다.
그리고 이에 맞춰 초기에는 2 stage object detection의 연구가 활발했던 것 같구요.
사실 이런 두가지 과정을 동시에 진행하는 1 stage의 결과물도
나쁘지 않은데 말이죠.
(비록 1 stage의 흐름이 인간의 사고과정과 달라보일지는 몰라도요.)
이처럼 모델의 아이디어를 떠올릴 때는
'사람은 어떤 과정으로 판단을 내리지?'를 생각한 뒤
이를 모델에 적용하는 경우가 많은 것 같습니다.
인간의 사고적 흐름을 딥러닝 모델 설계에 적용하는 것은
모델의 성능을 올리는데에
긍정적인 효과가 될 수도 있지만,
모델 설계의 아이디어를 제한시키는 경우도 있는 것 같습니다.
지난주 주말에 ResNet18에 대한 Grad-CAM을 구현하여 github에 올렸는데
조만간 이와 관련한 게시물을 올릴 계획입니다.
다만 부스트캠프 경연이 오늘부터 시작이라
언제 Grad-CAM에 대한 게시물을 올릴 수 있을지는 미지수네요ㅎㅎ
'이론 > 이미지인식' 카테고리의 다른 글
| [논문리뷰] FaceNet에 대한 이해 (1) | 2022.02.09 |
|---|---|
| [논문리뷰] DeepLabv3+의 이해 (0) | 2021.11.27 |
| [논문리뷰] Faster R-CNN 이해 (2) | 2021.04.12 |
| [논문리뷰] Fast R-CNN 이해 (0) | 2021.03.31 |
| [논문리뷰] R-CNN 이해 (0) | 2021.03.23 |



