
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 가상환경 확인
- pytorch 이미지 확인
- augmentation 이후 이미지 확인
- vscode sftp
- os 확인 명령어
- 프로그래머스 42839번
- gradient descent optimization
- 가상환경 제거
- 프로그래머스 67256번
- DeepLabv3+
- jupyter 명령어 모드 단축키
- Kullback-Leibler Divergence
- 백준 3190번
- YOLO detection
- 카카오 보석 쇼핑
- zip 압축해제 명령어
- jupyter 셀 추가 단축키
- 프로그래머스 67257번
- 프로그래머스 72410번
- 프로그래머스 67258번
- 프로그래머스 43164번
- 백준 효율적인 해킹
- 백준 1325번
- object detection
- 프로그래머스 42883번
- 프로그래머스 42885번
- 원격서버 로컬 동기화
- Optimization algorithms
- MMdetection
- 프로그래머스 보석 쇼핑
- Today
- Total
소소한 블로그
[논문리뷰] DeepLabv3+의 이해 본문
이 글에서는 DeepLabv3+모델 논문인
'Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation'
에 대해 다뤄볼 예정입니다.
(링크: https://arxiv.org/pdf/1802.02611.pdf)
이 논문을 읽어본 이유는지난 Semantic Segmentation 경연 때,
저의 최종 모델이 DeepLabv3+였기 때문입니다.
적어도 최종적으로 사용한 모델에 대해서는
논문을 보는 시간을 가져야겠다는 생각하에 이 글을 준비해봤습니다.
그러면 본론으로 들어가겠습니다!
[DeepLabv3+의 주요 특징과 각 특징의 장점]
먼저 DeepLabv3+의 주요 특징 먼저 나열하겠습니다.
ㆍASPP(Atrous Spatial Pyramid Pooling)
ㆍencoder-decoder structure
ㆍdepthwise separable convolution
각 특징의 장점을 간략히 설명하면 아래와 같습니다.
1) ASPP(Atrous Spatial Pyramid Pooling)
기본적으로 ASPP를 사용하기 때문에
하나의 이미지를 다양한 크기의 조각에서 바라볼 수 있게 되므로,
비교적 풍부한 문맥적인 정보를 추출할 수 있습니다.
DeepLabv3에서 쓰던 ASPP에 대한 설명은 여기서는 생략하도록 하겠습니다.
대신 Atrous convolution에 대한 내용은 아래에서 다시 다루도록 할게요.
(DeepLabv3 논문: https://arxiv.org/pdf/1706.05587.pdf)
(아래는 DeepLabv3에서의 ASPP 구조 사진)

2) encoder-decoder structure
encoder-decoder 구조를 사용하기 때문에
위에서 추출한 정보를 가지고 segmentation을 진행할 시,
물체의 경계가 모호하지 않도록 공간적인 정보를 최대한 유지할 수 있게 됩니다.
기본적으로 semantic information(=encoder의 output)은
encoding시에 pooling과 striding을 주는 convolution으로 인해
물체 경계와 관련된 정교한 정보들을 잃게 됩니다.
그렇다면 누군가는
'feature map(=semantic information)을 더 정교하게 만들면 되지 않나?'
라는 질문을 할 수 있을 겁니다.
하지만 논문에서는 (논문이 나온 시점에서) 성능이 좋은 neural network의 구조와
한정된 GPU 메모리를 고려했을 때,
feature map(encoder의 output)의 크기는 input 사진의 크기보다
8배이상 더 작아야 된다고 합니다.
아래 사진에서 왼쪽에서 3번째 사진은
위에서 언급한 ASPP와 encoder-decoder structure이 동시에 적용된 사진입니다.

3) depthwise separable convolution
depthwise separable convolution을 활용하기 때문에
정확도와 속도의 trade-off를 해결할 수 있습니다.
논문의 저자는 (논문이 나온 시점에서) 최근 depthwise separable convolution이 성공을 이뤘기 때문에,
semantic segmentation에서 사용하기에 적합하고
속도와 정확도 두가지 측면에서 모두 이점을 가지도록
기존 Xception model에 depthwise separable convolution을 적용했다고 합니다.
Xception model에 대한 내용은 여기서는 설명하지 않겠습니다.
(Xception 논문: https://arxiv.org/pdf/1610.02357.pdf)
(아래 사진은 Xception architecture)

그리고 수정된 Xception 모델은 ASPP모듈에 적용시켰다고 합니다.
depthwise separable convolution에 대한 더 자세한 설명은
아래에 작성해두었습니다.
[Atrous convolution / Depthwise seperable convolution / Deepabv3 / Decoder / modified Xception]
부제목이 너무 길죠?ㅎㅎ
다른게 아니라 이 논문의 chapter 3에서는 위와 관련된 짧막한 설명을 해주기 때문에,
여기에서도 각 개념에 대해 짧게 정리해보는 시간을 가지려 합니다.
위의 [DeepLabv3+의 주요 특징과 각 특징의 장점] 에서는
DeepLabv3+의 가장 대표되는 특징 3개와 이들의 장점에 대해 소개했다면,
이번에는 DeepLabv3+에 쓰이는 개념들에 대해 짧막하게 소개하는 과정이라고
생각하면 될 것 같습니다.
1. Astrous convolution
Astrous convolution은 DeepLab논문에 처음 등장한 용어입니다.
아래 사진의 위쪽 그림은 1차원에서의 일반적인 convolution이고,
아래 그림은 1차원에서의 astrous convolution 입니다.

이로인해 receptive field의 영역이 커지는 효과를 줄 수 있습니다.
논문에서는 receptive field를 'field-of-view'라고 표현했네요.
Astrous convolution을 수식으로 표현하면 아래와 같습니다.

여기서 r=1일때, 일반적인 convolution을 뜻하게 됩니다.
따라서 논문에서는 astrous convolution을 기존 convolution을 generalize한 버전이라고 표현하고 있습니다.
astrous rate값에 따라 receptive field의 크기가 달라지는것을 이용해,
(값이 클수록 receptive field 크기 또한 커지게 되겠죠.)
ASPP에서는 rate를 다양하게 하여 multi-scale 정보를 읽고 있습니다.
2. Depthwise separable convolution
Depthwise separable convolution은 일반적인 convolution을
두가지 과정을 통해 진행하는 것 입니다.
먼저 depthwise convolution을 진행하고,
pointwise convolution(1 x 1 convolution)을 진행하게 됩니다.
이것의 장점은 연산 복잡도를 크게 감소시켜준다는 것입니다.
아래 사진은 Depthwise separable convolution을 나타낸 것입니다.
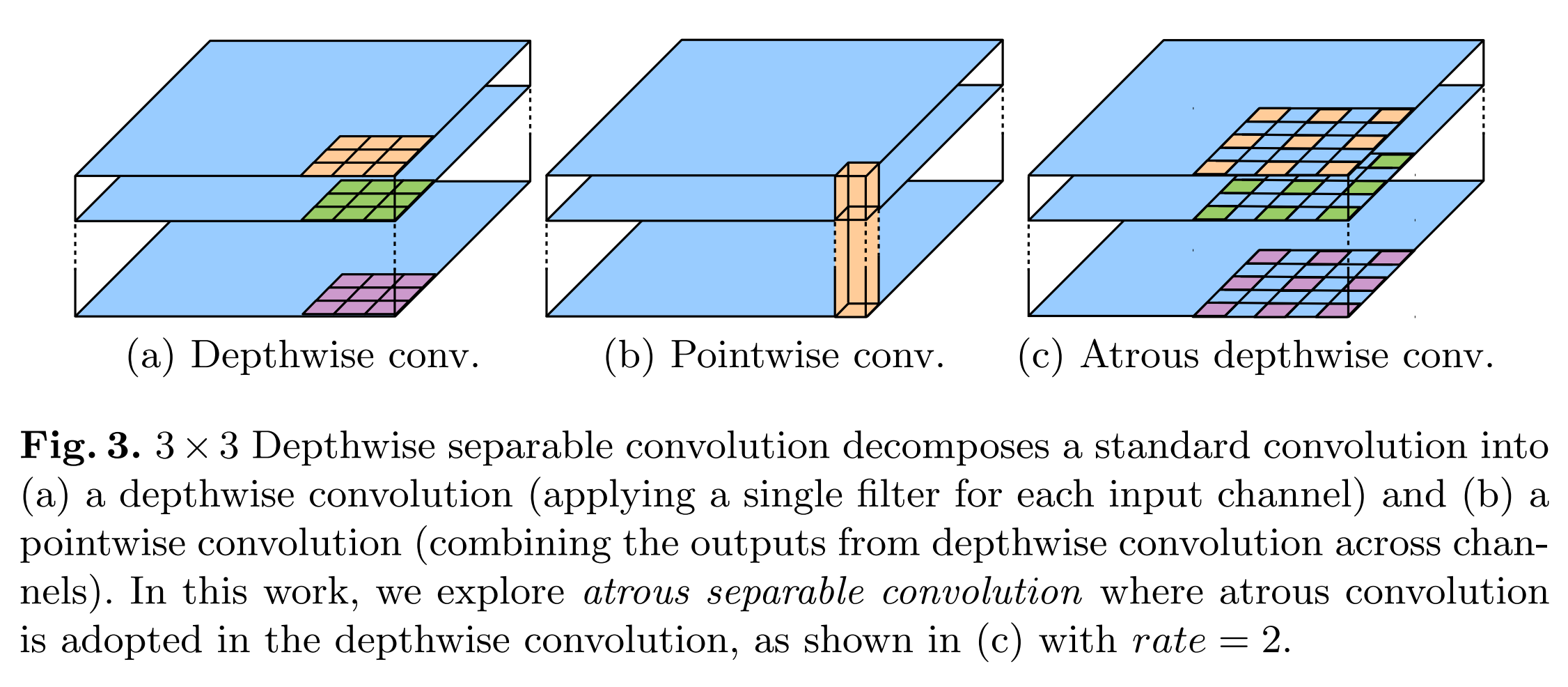
그림에서도 알 수 있다시피,
depthwise convolution은 각 채널마다 특정 커널이 존재하고,
이 커널을 통해 해당 channel에 대해서만 convolution을 진행합니다.
그 후 pointwise convolution에서는
depthwise convolution의 결과물에 대해서 1 x 1 convolution을 진행하게 됩니다.
이 논문에서는 Astrous convolution에다 Depthwise separable convolution을 적용시켰고,
이를 astrous separable convolution이라고 부르고 있습니다.
astrous separable convolution을 적용 시에
모델의 성능은 비슷하게 유지되지만
연산 복잡도는 크게 감소시켰다고 합니다.
3. DeepLabv3 as encoder
위에서 언급했다시피 DeepLabv3+에서는 encoder-decoder구조를 사용하고 있습니다.
이 때 encoder에는 기존 DeepLabv3모델의 구조를 사용합니다.
참고로 DeepLabv3에서도 ASPP를 쓴다는 것을 염두하시길 바랍니다.
4. Proposed decoder
DeepLabv3+의 이전 버전인 DeepLabv3는 output stride가 16입니다.
(모델의 최종 값의 크기가 input에 들어가는 이미지 크기보다 16배 작다는 의미입니다.)
DeepLabv3는 이를 bilinearly upsample을 해서
input 이미지와 해상도를 같게 해줬는데
이 과정에서 세밀한 경계값들의 정보가 손실된다는 문제점이 있었습니다.
그래서 전에 반복해서 언급했듯이 DeepLabv3+에서는 decoder를 도입한거구요.
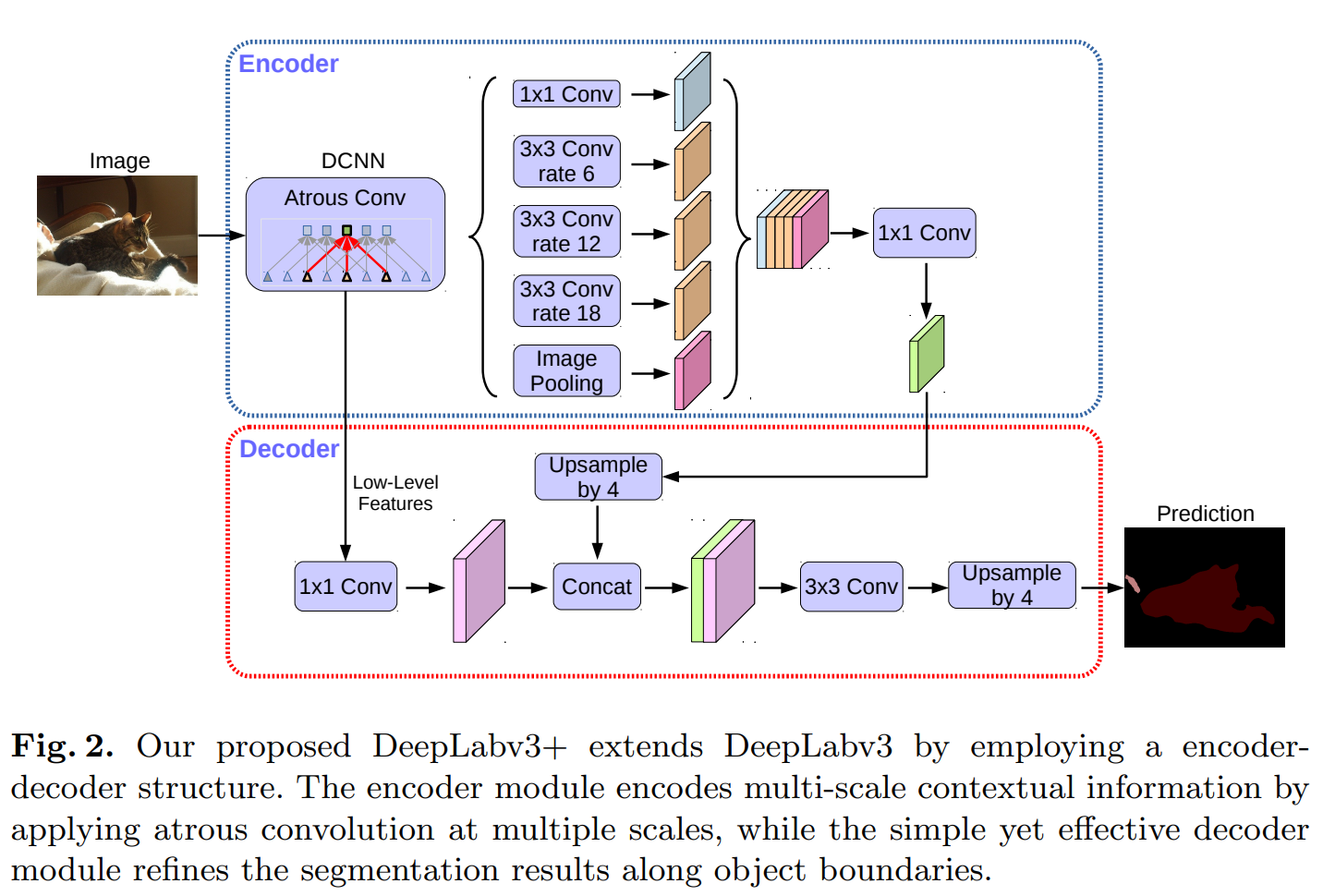
아래 그림은 DeepLabv3+ 구조를 나타냅니다.
파란색 큰 박스가 encoder, 빨간색 큰 박스가 decoder를 의미합니다.
5. Modified Aligned Xception
DeepLabv3+에서는 기존 Aligned Xception모델을
semantic segmentation에 적합하도록 수정하여 사용했습니다.
바뀐 점은 아래와 같습니다.
(1)
기존 Xception의 entry flow network structure은 건드리지 않되,
middle flow 부분을 더 깊게 만들었습니다.
(2)
모든 max pooling 연산을 stride를 가진 depthwise separable convolution으로 대체했습니다.
아마 정보의 손실을 막고자 이렇게 변경하지 않았나 싶습니다.
(3)
MobileNet구조와 비슷하게 3x3 depthwise separable convolution이 일어날 때마다,
batch normalization과 ReLU를 수행해줬습니다.
위 그림의 DCNN 과정은
수정된 버전의 Aligned Xception을 통해 이뤄집니다.
아래 그림은 수정된 Xception 구조 입니다.

[여러 실험들]
4장 Experimental Evalution에 등장한 실험에 대해 소개하겠습니다.
1. Decoder Design Choices
논문에서는 decoder가 어떤 구조일 때 좋은 성능을 내는지 소개하고 있습니다.
논문에서 실험한 바는 아래와 같습니다.
(1) encoder에서부터 온 low-level feature map의 channel을 몇으로 줄일 때 성능이 가장 좋은지
(2) 3 x 3 convolution 부분의 구조를 어떻게 했을 때 성능이 가장 좋은지
(1) encoder에서부터 온 low-level feature map의 channel을 몇으로 줄일 때 성능이 가장 좋은지
참고로 encoder에서부터 온 low-level feature map을
1 x 1 convolution을 통해 채널 수를 줄이는 과정은
아래 그림에서의 초록색 박스 부분입니다.

해당 실험의 결과는 아래 테이블과 같습니다.

위의 사진에서 보다시피 채널을 48로 줄일 때 제일 좋은 성능을 보여주고 있습니다.
(2) 3 x 3 convolution 부분의 구조를 어떻게 했을 때 성능이 가장 좋은지
참고로 3 x 3 convolution 부분은
아래 그림에서의 초록색 박스 부분입니다.
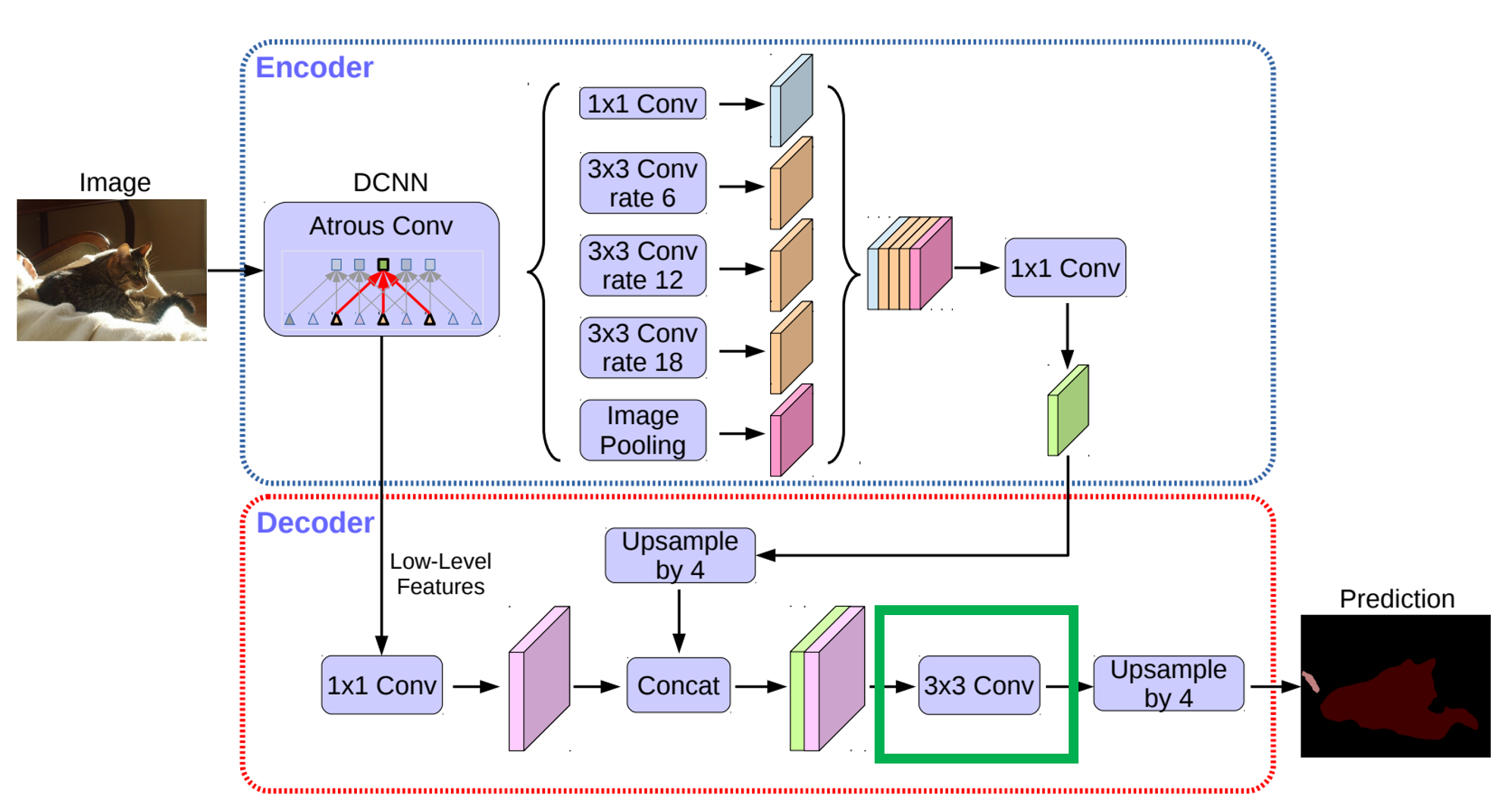
해당 실험의 결과는 아래 테이블과 같습니다.

위에서 보듯이 encoder의 Conv2 feature map과 encoder의 결과물을 concat한 것에 대해
[3 x 3, 256] convolution을 2번 했을 때가 제일 성능이 좋았습니다.
또한 encoder의 low-level feature을 Conv2이외에도 Conv3을 같이 썼을 때
Conv2만 썼을 때의 성능보다 안좋았기 때문에,
Conv2의 정보만 사용하기로 하였습니다.
2. ResNet-101 as Netwark Backbone
논문 저자들은 ResNet-101을 backbone으로 설정했을 때,
다양한 inference 전략을 성능과 연산량 두가지 측면에 대해 실험하였습니다.
아래는 이 실험을 테이블로 표현한 것입니다.
실험 주요결과는 사진 위에 필기해뒀습니다.
참고로 아래의 OS는 output stride를 뜻합니다.

3. Improvement along Object Boundaries
앞에서는 DeepLabv3+는 segmentation을 할 때,
더 정교한 경계선 정보를 얻기 위해 encoder-decoder 구조를 사용한다고 했습니다.
논문에서는 단순히 bilinear upsampling을 했을 때와
decoder를 사용했을 때의 성능을 비교해
과연 실제로 encoder-decoder구조가 경계선 정보를 잘 표현하는지 실험했습니다.
아래는 bilinear upsampling과 decoder를 사용했을 때의 성능을
비교한 그래프와 사진입니다.
(여기서 Trimap Width에 대해서는 소개하지 않겠습니다.)

(a)에서 특정 Trimap Width를 잡고 mIOU값을 비교한다면
bilinear upsampling했을 때 보다 decoder를 사용했을 때가 더 성능이 좋음을 알 수 있고,
(b)에서는 bilinear upsampling했을 때 보다 decoder를 사용했을 때가
더 경계선 정보를 잘 표현함을 알 수 있습니다.
4. Experimental Results on Cityscapes
아래 사진은 Cityscapes dataset에 대해
여러 모델의 testset mIOU값을 비교한 결과입니다.
(참고로 train dataset에는 coarse annotation도 포함해서 훈련시켰다고 합니다.)
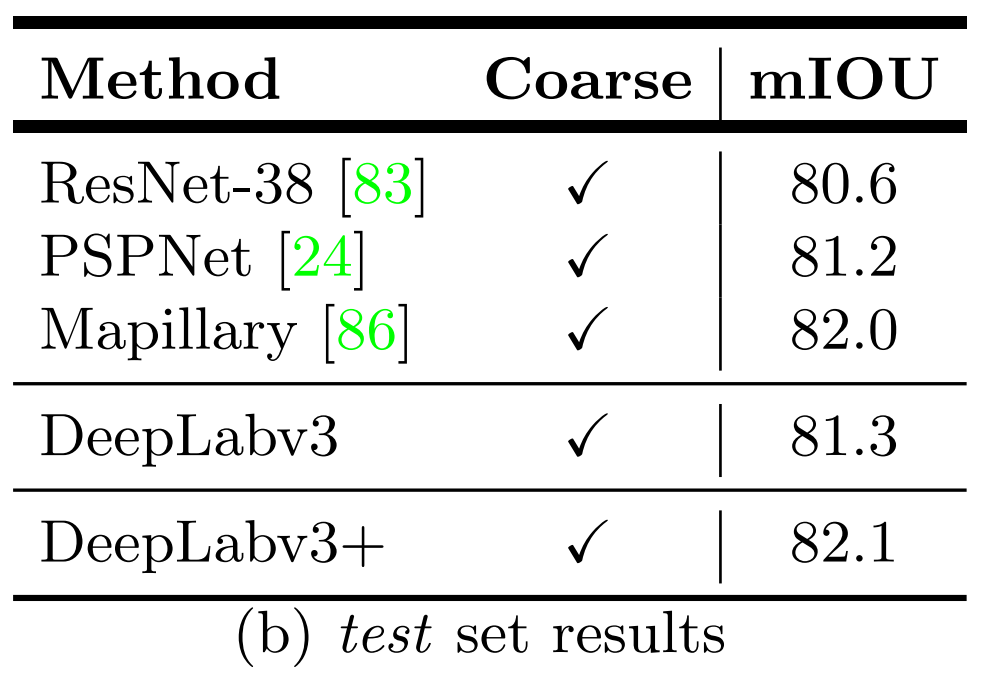
위에서 알 수 있다시피 DeepLabv3+는
논문이 나온 시점에서 Cityscapes dataset에 대해 sota를 차지했습니다.
[Conclusion]
드디어 Conclusion입니다!
지금까지 DeepLabv3+에 대해 살펴봤는데요.
수미상관같지만ㅎㅎ DeepLabv3+는 아래와 같이 요약됩니다.
ㆍASPP(Atrous Spatial Pyramid Pooling)
ㆍencoder-decoder structure
ㆍdepthwise separable convolution
처음 이 용어를 봤을 때보다
이 글을 읽고 위의 용어 3개에 어렴풋이 감이 잡혔다면,
제 목적은 달성하지 않았나 싶습니다.
이번 글은 다른 글보다 훨씬 시간이 많이 소요되었네요.
아마 논문의 많은 부분을 설명하고자 하는 욕심이 있었던 것 같습니다.
제가 이해한 바를 기록으로 남기는 것이
정말 가치있음을 알고 있지만,
이로 인해 다른 공부가 지연되는 것은 바람직한 방향은 아닌 듯하여
앞으로의 논문 리뷰는 핵심 위주로 정리할 예정입니다!
휴우 이제 드디어 다른 공부를 하러 가야겠습니다ㅎㅎ
'이론 > 이미지인식' 카테고리의 다른 글
| [논문리뷰] FaceNet에 대한 이해 (1) | 2022.02.09 |
|---|---|
| [논문리뷰] YOLO Object Detection의 이해 (0) | 2021.09.27 |
| [논문리뷰] Faster R-CNN 이해 (2) | 2021.04.12 |
| [논문리뷰] Fast R-CNN 이해 (0) | 2021.03.31 |
| [논문리뷰] R-CNN 이해 (0) | 2021.03.23 |



