
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 가상환경 제거
- augmentation 이후 이미지 확인
- jupyter 명령어 모드 단축키
- 프로그래머스 67258번
- 가상환경 확인
- YOLO detection
- 프로그래머스 67256번
- 프로그래머스 43164번
- pytorch 이미지 확인
- 프로그래머스 42883번
- 프로그래머스 42839번
- 프로그래머스 67257번
- 프로그래머스 42885번
- object detection
- gradient descent optimization
- 백준 효율적인 해킹
- zip 압축해제 명령어
- Kullback-Leibler Divergence
- 카카오 보석 쇼핑
- jupyter 셀 추가 단축키
- 프로그래머스 72410번
- 프로그래머스 보석 쇼핑
- 백준 1325번
- Optimization algorithms
- 백준 3190번
- vscode sftp
- DeepLabv3+
- 원격서버 로컬 동기화
- os 확인 명령어
- MMdetection
- Today
- Total
소소한 블로그
[9주차 - Day38] MMDetection 사용법 본문
* 해당 글은 2021.09.28에 임시저장만 했던 글로, 일부 수정해 2021.11.21에 업로드한 글입니다.
이번 글은 Object Detection 경연 진행 중 알게 된
MMDetection 사용법에 대해 일부 소개하고자 합니다.
여담을 말하자면,
Object Detection 경연에서는 새로운 라이브러리를 마주할 때의 대처능력을 길러보고자
한번도 경험해보지 않은 MMDetection을 사용해봤습니다.
MMDetection 사용법에 대해서는 원하는 자료가 많지는 않았었는데,
특히 한국어로 원하는 내용 찾기는 더 어려웠습니다.
저번 포스팅에서도 언급했지만 MMDetection은 공식 홈페이지 튜토리얼이 잘되어있으므로,
찾고자 하는 내용이 있으면 공식 홈페이지를 먼저 참고하고
그래도 없으면 기존의 github 코드를 뜯어보시길 바랍니다.
여기서 소개할 내용은 아래와 같습니다.
- 1. MMDetection의 config파일 형태
- 2. 새로운 데이터셋 사용방법
(조건: annotation형식이 coco형식을 그대로 따르되, 클래스 이름과 개수만 바뀐 경우) - 3. augmentation 변경 방법
- 4. backbone, neck, head, loss 변경 방법
- 5. optimizer 변경방법
1. MMDetection의 config파일 형태
먼저 공식 홈페이지에서는 아래와 같이 config파일 형태를 설명하고 있습니다.
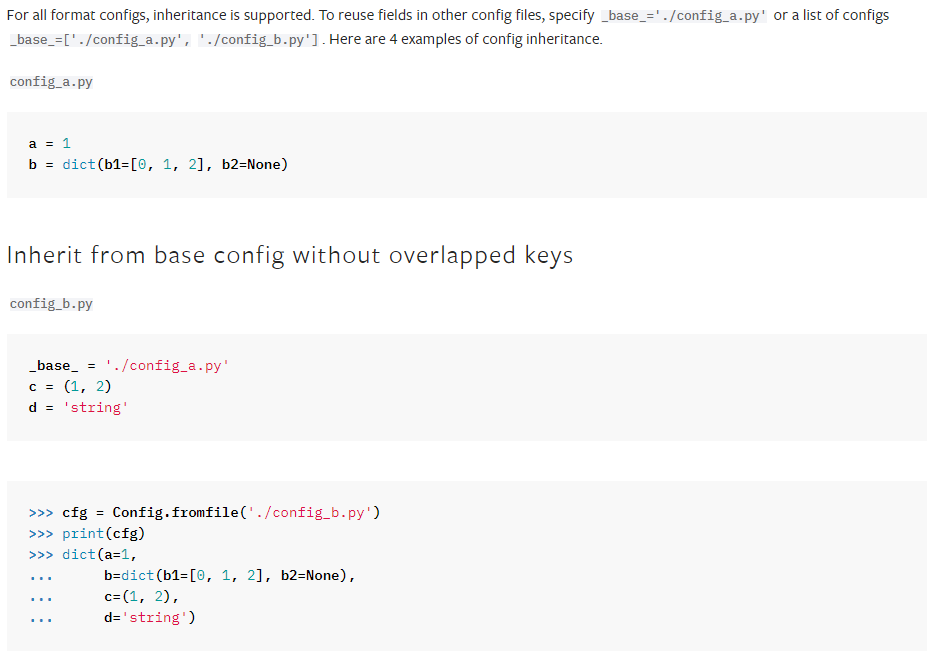
설명만 보면 감이 잘 잡히지 않으니, 실제 예시를 보겠습니다.
아래는 fast_rcnn_r50_fpn_1x_coco.py라는 이름을 가진 config파일입니다.

이 경우는, 아래의 config를 base로 삼고 있고 추가로 6 line부터 적혀진 설정값을 가지고 있습니다.
다시 말하자면 fast_rcnn_r50_fpn_1x_coco.py config파일은
아래 4개의 config에 적혀진 key:value값을 기본적으로 가지고 있으며
추가적으로 6 line에서부터 적혀진 key:value값을 가지고 있는 형태입니다.

2. 새로운 데이터셋 사용방법
(조건: annotation형식이 coco형식을 그대로 따르되, 클래스 이름과 개수만 바뀐 경우)
여기서는 새로운 데이터셋 이름을 trash라고 정의했습니다.
(참고로 진행했던 경연이 10가지 종류의 쓰레기를 Object Detection하는 태스크였습니다.)
또한 모델은 faster_rcnn_r50_fpn_1x을 쓴다는 가정하에 작성되었습니다.
1. 첫번째 방법
1-1) mmdetection > mmdet > datasets > trash.py (TrashDataset class) 를 새로 생성한다.
* 내용은 coco.py를 복붙하되, 클래스 명과 CLASSES변수값만 커스텀하도록 한다.
1-2) mmdetection > configs > _base_ > datasets > trash_detection.py 를 새로 생성한다
* 내용은 coco_detection.py를 복붙하되, dataset_type과 data_root dict값을 변경한다. (데이터 경로도)
1-3) mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
* 내용은 faster_rcnn_r50_fpn_1x_coco.py를 복붙하되, '../_base_/datasets/coco_detection.py',를 변경한다.
2. 두번째 방법
mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
* 내용은 faster_rcnn_r50_fpn_1x_coco.py를 복붙하되, 아래를 참고하여 key:value를 커스텀하여 추가한다.

3. augmentation 변경 방법 (mmdetection에서는 pipeline 과정에서 augmentation이 수행)
1. 첫번째 방법
1-1) mmdetection > configs > _base_ > datasets > trash_detection.py을 생성한다.
* 내용은 coco_detection을 복붙하되, train_pipline과 test_pipeline의 값을 바꿔준다.
1-2) mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
* 내용은 faster_rcnn_r50_fpn_1x_coco.py를 복붙하되, '../_base_/datasets/coco_detection.py',를 변경한다.
2. 두번째 방법
mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
* 내용은 faster_rcnn_r50_fpn_1x_coco.py를 복붙하되, config file에서 train_pipeline과 test_pipeline의 value값을 수정한다.
참고

4. backbone, neck, head, loss 변경 방법
어떻게 바꿔야하는지는 공식 홈페이지 튜토리얼에 잘 나와있으므로 아래 url을 참고하면 됩니다.
https://mmdetection.readthedocs.io/en/latest/tutorials/customize_models.html
Tutorial 4: Customize Models — MMDetection 2.17.0 documentation
Tutorial 4: Customize Models We basically categorize model components into 5 types. backbone: usually an FCN network to extract feature maps, e.g., ResNet, MobileNet. neck: the component between backbones and heads, e.g., FPN, PAFPN. head: the component fo
mmdetection.readthedocs.io
대신 기존 MMDetection에 등록된 backbone, neck, head, loss를 확인하는 방법은
아래의 github코드를 참고하면 됩니다.
mmdetection에 등록된 backbone 확인: mmdetection/mmdet/models/backbones
mmdetection에 등록된 neck 확인: mmdetection/mmdet/models/necks
mmdetection에 등록된 head 확인:
mmdetection/mmdet/models/roi_heads
mmdetection/mmdet/models/seg_heads
mmdetection에 등록된 loss 확인: mmdetection/mmdet/models/losses
5. optimizer 변경 방법(조건: pytorch에서 지원하는 optimizer로 변경하고 싶은 경우)
MMDetection은 PyTorch에서 지원하는 optimizer를 모두 사용가능하게 하고 있습니다.
optimizer를 변경하는 방법은 아래와 같습니다.
1. 첫번째 방법
1-1) mmdetection > configs > _base_ > schedules > schedule_1x_##를 생성한다.
* schedule_1x.py를 복붙하되, optimizer의 value값을 변경한다.
1-2) mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
* 내용은 faster_rcnn_r50_fpn_1x_coco.py를 복붙하되, '../_base_/schedules/schedule_1x.py',를 변경한다.
2. 두번째 방법
mmdetection > configs > faster_rcnn > faster_rcnn_r50_fpn_1x_trash.py를 새로 생성한다.
아래 사진 처럼 optimizer를 지정해준다.

예전에 작성된 글을 다듬어서 업로드합니다.
확실히 시간이 지난 후 다듬으려고 하니 기억이 희미해서,
그때 그때의 기록의 중요성을 다시 한번 느꼈습니다.
MMDetection을 사용하면서 config단위로 쉽게 모델을 변경할 수 있어서 좋았습니다.
이로인해 다양한 조합을 빠르게 실험시킬 수 있었어요.
또한 새로운 라이브러리를 마주할 때에 단시간에 적응하는 능력을 기를 수 있었습니다.
하지만 MMDetection에 등록된 모델에 한해서 실험을 돌리다보니,
최신 Transformer 계열의 SOTA 모델을 실험하지 못했던 것이 조금 아쉽긴 합니다.
'부스트캠프 AI Tech' 카테고리의 다른 글
| [4주차 - Day19] pre-trained model의 transfer-learning (0) | 2021.12.04 |
|---|---|
| [13주차 - Day55] MMDetection의 pipeline을 custom하는 법 (0) | 2021.10.25 |
| [12주차 - Day51] COCO 데이터 형식 EDA (0) | 2021.10.20 |
| [11주차 - Day48] 정리안된 기록 (0) | 2021.10.19 |
| [8주차 - Day36] VSCode에서 로컬과 원격서버 동기화하기 (4) | 2021.09.24 |
