
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 가상환경 제거
- 카카오 보석 쇼핑
- 백준 1325번
- 프로그래머스 42883번
- augmentation 이후 이미지 확인
- YOLO detection
- object detection
- 백준 3190번
- DeepLabv3+
- 백준 효율적인 해킹
- jupyter 셀 추가 단축키
- 프로그래머스 보석 쇼핑
- 프로그래머스 42839번
- 프로그래머스 43164번
- Kullback-Leibler Divergence
- zip 압축해제 명령어
- pytorch 이미지 확인
- jupyter 명령어 모드 단축키
- 프로그래머스 72410번
- 프로그래머스 67256번
- gradient descent optimization
- Optimization algorithms
- vscode sftp
- 프로그래머스 67258번
- 가상환경 확인
- os 확인 명령어
- 프로그래머스 67257번
- 프로그래머스 42885번
- 원격서버 로컬 동기화
- MMdetection
- Today
- Total
소소한 블로그
[4주차 - Day17] 간단한 multi-class 이미지 분류기 구현(end-to-end) 본문
이미지 분류 경연을 위해
간단한 multi-class 이미지 분류기를 end-to-end 구현해봤습니다.
혼자 모델을 구현해본 적이 없기 때문에,
아래 사항들에 초점을 맞춰 대략적인 base line code를 작성해봤어요.
1) 아주 간단한 Custom Model 정의 (※ net과 net사이의 parameter 개수 고려)
2) 주어진 데이터셋에 맞춰 Custom Dataset 정의
3) Dataset에 넘겨줄 input data, label data 가공 (※ csv와 파일명으로부터 labeling 진행)
4) Training이 진행되는지 확인
5) 훈련된 Model로 부터 Inference
어떤 점이 개선되어야 하는지는
구현에 대한 설명을 끝낸 후 소개해드리겠습니다.
아래는 제가 작성한 코드에 대한 설명입니다.
구현에 대한 설명에 앞서 경연측에서 주어진 데이터를 이해해야할 필요가 있습니다.
train data의 디렉토리 구성은 아래와 같습니다.

train.csv를 읽어서 head()를 프린트 해보면 아래와 같은 정보를 볼 수 있습니다.
(gender, age, 사진에서 마스크를 쓴 형태) 에 따라 0~17 까지 총 18개의 class를 정의하지만,
(* 참고로 마스크를 쓴 형태는 사진파일명에서 알 수 있습니다.
또한 아래에서 보이는 path는 이미지파일 path가 아닌 한사람의 폴더 path입니다.
해당 path에 어떤 사진들이 있는지는 바로 아래에서 설명됩니다.)
csv파일에서는 class를 직접적으로 주지 않습니다.
따라서 이미지에 대한 class labeling을 따로 해줘야 합니다.

images 폴더의 구성은 아래와 같습니다.
images 안에는 여러가지 폴더로 나눠져 있고,
(* 참고로 각 폴더는 위에서의 path와 매핑됩니다!)
그 폴더는 7장의 사진으로 구성되어 있습니다.

또한 하나의 이미지 파일은 (3, 512, 384)의 사이즈를 가집니다.
이제 본격적으로 구현한 모델에 대해 설명해보겠습니다.
0. Library 불러오기 및 경로 설정

1. Cumstom Model 정의

모델 자체는 아주 간단합니다.
2개의 convolution과 3개의 fully connected layer로 구성되어 있습니다.
여기서 신경썼던 부분은 파라미터개수였습니다.
사실 pre-trained된 모델을 쓰면
위처럼 모든 layer의 parameter수를 고려하는 경우는 별로 없겠지만,
모델구현을 공부하는 입장으로서
직접 parameter수를 생각해보고 싶었습니다.
추가로 처음에 flatten을 할 때에는 모든 차원에 대해서 flatten을 했습니다.
예를 들면 (3, 2, 2, 2)의 shape을 가진 tensor가 있다고 가정하면,
3 * 2 * 2 * 2의 벡터로 만들어 주는 형식으로요.
이 경우에는 모델을 학습 시 에러가 나게 됩니다.
항상 batch가 있다는 것을 고려하고,
첫번째 차원은 그대로 두고 나머지를 flatten을 해야한다는 것을 기억해야합니다.
2. Custom Dataset정의 (문제에서 주어진 데이터셋에 대해 적합하게 구현하기)
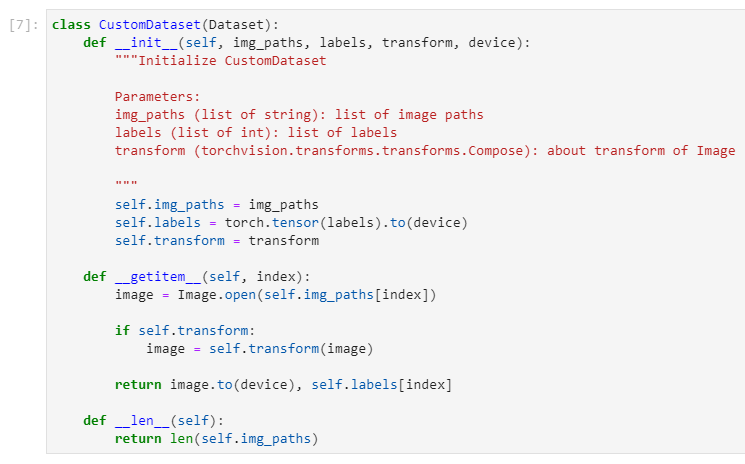
이 부분에서 가장 신경썼던 부분은
현재 경연에서 주어진 데이터 셋에 대해서
어떻게 하면 가독성 좋은 Custom Dataset을 만들 수 있을까였습니다.
예시를 들면,
labels(이미지의 클래스)의 텐서화는 Dataset에서 이뤄지는게 좋을지,
아니면 애초에 Dataset의 파라미터로 labels(이미지의 클래스)를 텐서화해서 넘겨주는것이 좋을지
였습니다.
위의 Docstring에서 알 수 있다시피
저는 Dataset의 파라미터로 list형태의 img_paths, labels를 넘겨주었고
Dataset에서 해당 리스트를 텐서화해서 return을 반환해주게끔 구현했습니다.
3. CustomDataset에 넘겨줄 input data, label data 가공 (문제에서 주어진 데이터에 대해 적합하게 구현하기)

Dataset에 넘겨줄 img_paths와 labels를 가공하는 작업입니다.
+) Custom Model의 Test
위의 1, 3단계에 에러가 나지는 않는지 중간 실험을 해봤습니다.
에러없이 나오는 것을 확인할 수 있습니다.

4. DataLoader정의

5. Accuracy 계산 함수 정의 및 Train
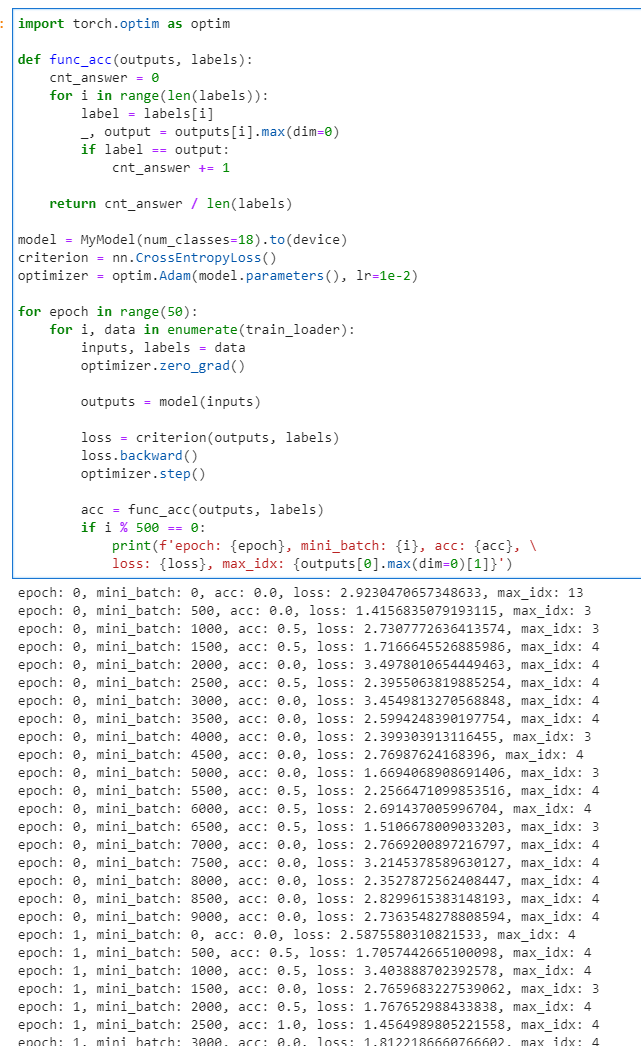
사실 이 부분에서 시행착오가 있었습니다.
처음에는 위의 완성본 custom model과 다른 코드였습니다.
학습을 진행해도 loss가 줄어들지 않길래,
아래와 같은 시도를 해봤습니다.
1)
optimizer와 learning rate를 변경해보면서 실험해봤습니다.
그래도 loss가 줄지 않았습니다.
2)
그래서 이게 실제로 parameter의 weight가 변경되고 있는지 확인하기로 했습니다.
model의 state_dict를 통해 하나의 파라미터 이름을 고른후,
backward가 진행될 때마다 해당 파라미터의 weight 값을 살펴봤습니다.
그 결과 weight가 변하지 않고 있음을 알아냈습니다.
이 현상을 이해하려면 'Parameter'에 대해 알아야 합니다.
train시에 backward를 하면 model의 weight가 업데이트 됩니다.
더 자세하게 말하자면,
train시에 backward를 하면 model의 'Parameter'로 등록된 변수들의 weight가 업데이트됩니다.
저는 특정 레이어를 Parameter로 등록하지 않은채로
forward시에 연산해버려서
해당 문제가 발생했던 것입니다.
이를 발견하고 CustomModel을 다시 정의했습니다.
이와 별개로 완성된 코드에서의 학습 진행결과를 보면(위의 사진),
성능이 좋지 않음을 알 수 있습니다.
이는 아마 현재 model의 layer가 얕고
또한 dataset의 분포도가 한쪽으로 치우쳐져 있기 때문이라는 생각이 드네요.
마지막 Inference단계의 코드는
경연측에서 준 baseline코드를 활용했기 때문에,
여기서는 소개해드리지 않기로 하겠습니다.
위는 주어진 data에 대해서
간단한 multi-class 이미지 분류기의 end-to-end 구현에 초점을 맞췄기 때문에,
여러가지면으로 부족한 점이 있습니다.
1) 모델의 정확도
2) train / validation 이 구분되어 있지 않음
3) 모델 저장
등등
따라서 이제 수정해볼 사항들은
1) pre-trained model을 불러오고 fine-tuning 시키기
2) loss가 낮은것으로 갱신될 때마다 model save하기
3) train/val set 나누기
4) image augmentation
입니다.
위의 4가지 사항을 구현을 해본 뒤,
모델의 정확도를 높이기 위해
parameter 조정이나 classifier의 layer 형태 변환 등을
실험해볼 듯 합니다.
'부스트캠프 AI Tech' 카테고리의 다른 글
| [8주차 - Day36] VSCode에서 로컬과 원격서버 동기화하기 (4) | 2021.09.24 |
|---|---|
| [6주차 - Day27] Augmentation 적용 결과 시각화하기 (2) | 2021.09.09 |
| [4주차 - Day15] F1 Score (0) | 2021.08.23 |
| [4주차 - Day15] VSCode ssh 접속 (0) | 2021.08.23 |
| [2주차 - Day7] Gradient Descent Optimization Algorithms (0) | 2021.08.12 |


